
Book 5: What is Memory?
| Previous | Next |

Everything understood so far? Good, because the next thing is a point where many beginners feel overwhelmed by the arcane concept that is the “pointer”. So, we are going to take a short detour and illustrate how a computer manages memory internally, which will make all of this become much clearer, and open up access to a great tool for every programmer.
Why can’t I just use variables?
The mean part about memory management in C is that some of your memory management is done for you. This is very convenient, but also poses a stumbling block for people with moderate to advanced needs, who are frequently surprised by the seemingly arbitrary limits of variables. To make these comprehensible, I will quickly illustrate the basic workings of memory, then how they apply to variables. This will make the limitations of variables obvious, and from there it will be a small step towards pointers.
What is memory?
It helps if you think of computer memory (aka RAM) as something akin to a piece of coarse graph paper, with those boxes on it. Computer memory is one huge sheet of such paper, with each box representing one byte in memory.
As you may or may not already know, a byte can hold a number from 0 to 255. If you want memory to hold anything else than such a number, you have to re-interpret that number. E.g. if you want to store some text in memory, what you do is use a number for each character. E.g. 65 could be A, 66 could be B etc.
If you want to keep numbers larger than 255 in memory, you have to use several bytes to represent a single number. I don’t want to bore you with the details, since most programming languages take care of that behind the scenes. It’s generally enough to know that bigger numbers can be stretched out across several bytes.
Want the gory details? Well, imagine a byte could only hold numbers from 0 through 9: You’d simply use a byte for each digit. To calculate the actual number, e.g. for 19, you’d multiply each digit with its magnitude. The rightmost digit always has the magnitude 1, and each digit’s magnitude has one 0 more than the one before it. I.e. for 19, you multiply the first digit, 9, by 1: 1 * 9 = 9. The second digit has the magnitude 10, so you’d add 10 * 1 = 10 to it. That’d give you 19. If you wanted to express 255 this way, you’d do 2 * 100 + 5 * 10 + 5 * 1 = 200 + 50 + 5 = 255.
Now, since a byte can hold more numbers, those from 0 through 255, it’s of course a little different in reality. If you’re really curious, check out what a maths textbook has to say about different bases for numbers. Our normal numbers are base 10, that is, each digit can have ten different values (0 through 9). A bit can have two different values (0 and 1), so a bunch of bits can be used to express numbers with base 2 (which is actually what the computer does for each byte under the hood). To express a bigger number using bytes as digits, you’d have to express it in base 256, because a byte can hold 256 different values (0 through 255).
Now, just as you start writing on a piece of graph paper in the upper left and then keep writing towards the right, and then you wrap to the next line and continue writing from left to right again, the computer will write each variable into memory in sequence. To be able to later refer to the different pieces in memory, each box on the paper has been numbered. The first one in the upper left has the number one, the second one just to its right has the number two, the last one on that line may have the number 1000, and the first one on the second line has the number 1001, and so on, and so forth. This number is what we call that byte’s address.
So, whenever you declare a variable named myCharacter, the computer picks the first empty box on the paper (e.g. box number 32), and makes a note that whenever you’re saying myCharacter, you’re actually referring to the contents of box no. 32.
There’s one peculiarity you should be aware of, though: Since a byte inside computer memory can only hold numbers from 0 to 255, and has no value for “empty”, the computer keeps track of the first unused byte in memory by simply remembering its address, in the so-called “stack pointer”, which “points” at the end of our used memory. So, if you had 32 variables which each take up one byte, and thus numbered 1 to 32, the computer would remember the number 33 in its “stack pointer”.
Why “stack”? Well, since we are only remembering the end of our used memory, there may be no “holes” in our unused memory. After all, how would the compiler know that these “holes” are unused and available? We’d be wasting precious memory. Since there are no holes in our block of unused memory, our variables appear “nicely stacked up one on top of the other” (well, if you rotate the sheet of graph paper counterclockwise, at least).
Can you already see the problem? Imagine you had a function that has three variables. Two of them (A and C) were one byte in size, the other (B) would be variable in size. Imagine the one of dynamic size had been declared second, thus being in the middle of the other two. They would maybe all start out being one byte in size. Then comes the time where the second variable needs to be resized. Here’s what happens when we enlarge B to be four bytes long:
Ouch! Because our code doesn’t remember variables by name, but rather by their address, and we moved C from address 3 to 6, the next time our code tries to change the variable C, it will still write to memory location 3, and thus overwrite the second byte of B.
Since it would be a lot of work (and almost impossible) to go through the code and change every occurrence of the address 3 to 6, the programmers decided that variables needed to have a fixed size that was known at compile-time.
In reality, we’d also have to store the stack pointer somewhere. So, what the computer actually does is reserve some special place, e.g. the first four bytes of memory, for the stack pointer. This in turn would mean that “A” would actually be at address 5, B would start at address 6, and C would start first at address 7, and at address 10 after B is resized.
One kind programmer of the GNU C Compiler has actually extended the compiler to allow creating – within limits – variables with variable sizes. However, this is simply a sleight of hand pretending to provide stack variables that can be resized, and will thus be ignored in this article.
Introducing: The heap
While the orderly stack is very convenient for fixed-size things like variables in calculations, and is also very fast and effective due to the fact that all you do to enlarge or shrink the stack is really just adding to or subtracting from the memory address in the “stack pointer”, it is completely impractical if you want to work with dynamic memory.
Of course, the people who designed today’s computers realized the same. So, in addition to the orderly stack that keeps fixed-size items, they invented the rather unordered “heap”. While the stack starts at the top of the computer’s memory and grows towards the bottom, the heap begins at the bottom of the memory (i.e. the lower-right corner of our piece of graph paper) and grows toward the top (towards the left, and then upwards on our piece of graph paper):
Now, keeping track of the stack was easy. We just put the items one after the other, and since we knew their position and their size when we wrote our program, we don’t need any more info than where they end, which we kept in the stack pointer. Since “keeping track of anything” on a computer requires reserving memory for it, we simply went and reserved the first four bytes on the stack to keep the stack pointer there.
But how do we keep track of the separate chunks of memory scattered all throughout the heap? And how do we remember where the heap has “holes” which can still be used when the program needs some memory?
Well, just as we reserved some memory for the stack pointer, we reserve some for the start of our heap. If the heap is empty, the heap start-pointer is zero. But that’s not enough. So, what we do in addition to that is we add a “header” in front of every chunk of memory. This header notes the size of our block of memory, as well as the address of the next block of memory on the heap.
What we have now, is like a game of ‘Telephone’: You start at the end of your memory, where the heap-start-pointer is. You read the pointer and now you know where the first block is. Then you go to the address the first pointer points to, and there you find a pointer to the second block, follow that, and there you also have a pointer to the third one, and so on. This is commonly called a linked list.
Obviously, this is very wasteful for small amounts of data. Typically, to keep track of a single chunk of memory requires 8 bytes to hold the size, and 8 bytes to hold the pointer to the next block of memory. For each additional chunk, even if it is only one byte long, these eight bytes are required again, in addition to the one byte actually needed to store the chunk itself. That is the reason why we still have the stack, even though the heap is much more flexible.
Now, when you need to resize a chunk of memory that is stuck between two others, the computer can simply “punch a hole” in the heap, removing the small memory chunk and instead creating a second one that is larger, which you can now use. Since the computer knows where and how large each memory chunk on the heap is, it doesn’t have a problem with holes, and it can even re-use the “holes” when somebody else needs that much memory.
Of course, since the memory chunk moves when it is resized, you can’t use the old address to refer to it anymore. The computer will let you know the new one, and the program will need to be written to always use the current address.
You may be wondering why the stack starts at the top, while the heap starts at the bottom. There is a simple rationale for that: By making them start at the opposite ends of the computer’s memory, you prevent them from accidentally colliding. After all, if we just decided that the heap started 1000 bytes after the start of the stack, there would be a very strict size limit on the stack. If the stack grew to 1000 bytes, it couldn’t grow any further without overwriting the heap. The same could happen the other way round.
Of course, there is still a possibility of the stack and the heap colliding, but now the user can avoid it by installing more memory in their computer.
What I described above is basically what the C memory management functions do. C provides malloc() which looks at the memory and reserves a chunk of memory with the proper size, and realloc() reserves a new, larger part of memory and gets rid of the old one. However, the pointer they give you always points to your data, so you don’t have to worry about those 8 additional bytes when using it.
Many modern computers are smart enough to keep the stack and the heap from colliding, and thus do not really keep them at opposite ends of memory anymore. Still, the way they do it would involve lots of information about page tables and virtual memory, and aren’t really relevant to understanding the basics of memory.
What does that have to do with pointers?
As the attentive reader will have realised, a pointer is nothing else than the address of a chunk of memory. It doesn’t matter whether it points to memory on the stack or on the heap. Memory is memory, and in most cases we needn’t be choosy. Take note of the implications this has: A memory address is simply a number. As such, we can store it in a regular variable on the stack, and we can do maths with it. We can add to it, we can subtract from it, etc.
Now, why would we want to add something to a memory address? Well,imagine you wanted to keep a range of text, e.g. ‘Atkinson’, in memory, on the stack. Since every byte is a character, and ‘Atkinson’ is 8 characters long, you would reserve 8 bytes of memory for it. Now, to be able to access each character in this range of text, you’d have to remember the eight addresses of the eight characters. What a waste!
So, what you do instead is take a step back, and look at the memory:
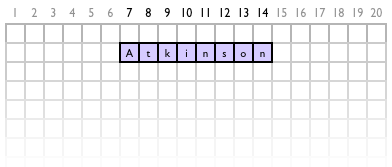
Since we just reserved the memory for one character after the other (and on the stack), they happen to be in a single row. Also, their addresses are in sequence. So, what we can now do is simply remember the address of the first character, in our example 7. Now, whenever we want to access one of the other characters, we simply add to the pointer to the first character we kept. The first character is at address 7 + 0,the second character is at address 7 + 1, the third is at 7 + 2 …notice a pattern? The character with the number n is always at address 7 + (n-1). So, by remembering the address of a block of memory and an “offset” or “index” (i.e. n-1), we can easily manage lists in memory.
Moreover, to store this piece of text on the heap, we just request one large block, and only have to “pay” the 16-byte penalty we need for the length byte and the “next” pointer once. And we don’t need 17 bytes per character; instead of 136 bytes in total to store 8 one-byte characters, we’ll only need 24.
As you will see later, this numbering scheme is used in C to refer to items in arrays, and to characters of strings.
The process of adding to/subtracting from a memory address is usually referred to as “pointer arithmetics”.
Keep in mind that you are not guaranteed to get a whole, uninterrupted block of bytes in a row if you request the bytes separately. If you reserve memory for a list of some sort as illustrated above, you will want to request one block large enough to hold all list items, and only then you’ll be able to use pointer arithmetics to get at the characters.
What about * and &? And what does “de-referencing” mean?
Mind your language! … err … Well, when you keep a memory address (i.e. a pointer) in a variable, what you have in this variable is not the memory itself. Rather, you have a “reference” there. Now, the problem with this reference is that all operations you do (like add, subtract …) work on the reference, i.e. they change the address, they perform pointer arithmetics.
De-referencing is the process of telling the computer to go to the memory address you have here, and to manipulate the memory itself. To do that in C, you use the “follow-address operator”, *. So, when you have a memory address in a pointer variable m, *m += 1 essentially tells the computer to first “walk over to that address”, and to then add 1 to whatever it finds there.
Of course, a pointer can point to any kind of variable, even to another pointer. So, **m += 1 would mean
- follow the first pointer
- treat whatever is there as a pointer
- follow that second pointer
- add one to whatever the second pointer pointed to
which, again, could be an integer, a character, or even yet another pointer. Neat, huh?
And finally, the &-operator, also known as “address-of”. The address-of-operator simply tells the computer to give you the memory address at which a particular variable is located. You can then stuff this address in a pointer variable and perform pointer arithmetics on it, or whatever you want.
Any additional questions?
Well, this concludes our short but hopefully insightful tour through the memory of your computer. I hope it has helped you.
| Previous | Next |